머신러닝
K-Means의 WCSS와 Elbow Method
zzuvely
2022. 5. 9. 17:45
K-Means 알고리즘의 k를 정하는 방법
WCSS(Within Clusters Sum of Squares)
1) 적절한 k 값(몇 개 그룹)을 찾기 위해서는 WCSS 값을 확인해야 한다.
2) 따라서 k는 1부터 10까지 다 수행해보고
3) WCSS 값을 확인해 본다.
4) 이때 엘보우 메소드를 이용해서 최적의 K 값을 찾도록 한다.
wcss = []
for k in range(1, 11) :
kmeans = KMeans(n_clusters= k, random_state=42)
kmeans.fit(X)
wcss.append(kmeans.inertia_)
plt.plot(range(1, 11), wcss)
plt.title('Thew Elbow Method')
plt.xlabel('Number of Clusters')
plt.ylabel('WCSS')
plt.show()

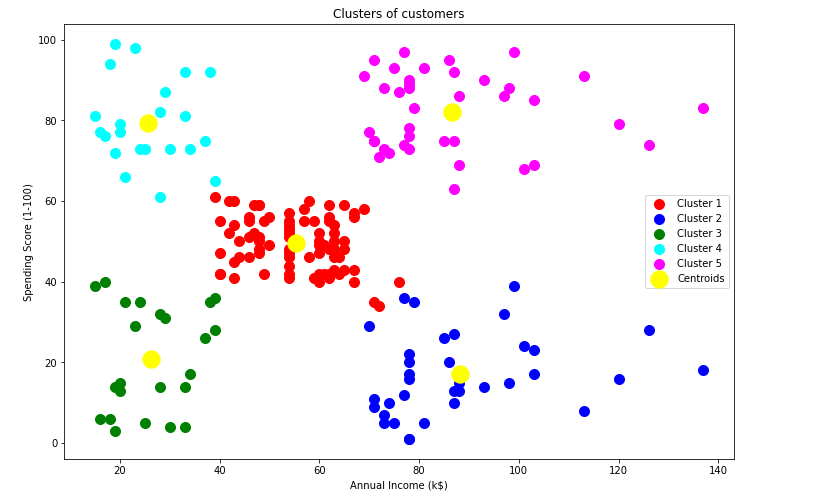
찾은 k 값으로 KMeans 알고리즘을 통해 k개의 그룹을 만든다.
kmeans = KMeans(n_clusters=5, random_state=42)
y_pred = kmeans.fit_predict(X)
y_pred

새로운 컬럼 'Group'을 만든 후, 예측한 군집화 데이터를 넣어준다.
df['Group'] = y_pred
df

plt.figure(figsize=[12,8])
plt.scatter(X.values[y_pred == 0, 0], X.values[y_pred == 0, 1], s = 100, c = 'red', label = 'Cluster 1')
plt.scatter(X.values[y_pred == 1, 0], X.values[y_pred == 1, 1], s = 100, c = 'blue', label = 'Cluster 2')
plt.scatter(X.values[y_pred == 2, 0], X.values[y_pred == 2, 1], s = 100, c = 'green', label = 'Cluster 3')
plt.scatter(X.values[y_pred == 3, 0], X.values[y_pred == 3, 1], s = 100, c = 'cyan', label = 'Cluster 4')
plt.scatter(X.values[y_pred == 4, 0], X.values[y_pred == 4, 1], s = 100, c = 'magenta', label = 'Cluster 5')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s = 300, c = 'yellow', label = 'Centroids')
plt.title('Clusters of customers')
plt.xlabel('Annual Income (k$)')
plt.ylabel('Spending Score (1-100)')
plt.legend()
plt.show()