머신러닝
머신러닝 - Linear Regression ( 선형 회귀 )
zzuvely
2022. 5. 6. 18:06
머신러닝에서 신규데이터 예측하는 순서
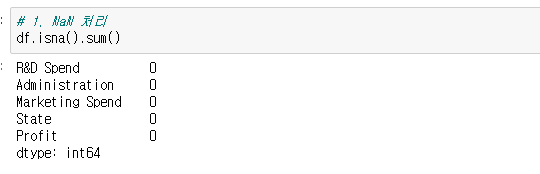
1) NaN 이 있는지 확인하고 처리해준다.
2) X, y로 데이터를 분리해준다. X는 2차원이어야한다.
인공지능 학습하는 fit 함수에 X 값을 2차원으로 넣어야 동작하기 때문이다.
X값이 1차원이라면 reshape 함수를 사용해서 2차원으로 만들어주어야한다.


3) 피쳐스케일링한다. - StandardScaler (표준화), MinMaxScaler (정규화) 방법이 있다.
단, Linear Regression 라이브러리는 자체에서 피쳐스케일링을 해주므로 이 과정을 생략한다.
4) 분석할 컬럼의 데이터가 문자열이라면 숫자로 바꿔준다. - Label Encoding 방법과 OneHot Encoding 방법이 있다.

5) 데이터셋을 학습용과 테스트용으로 데이터를 분리한다.
데이터중 80%는 학습용으로, 20%는 테스트용으로 설정해주었다.

6) 인공지능 모델링 - LinearRegrssion(선형회귀) 사용

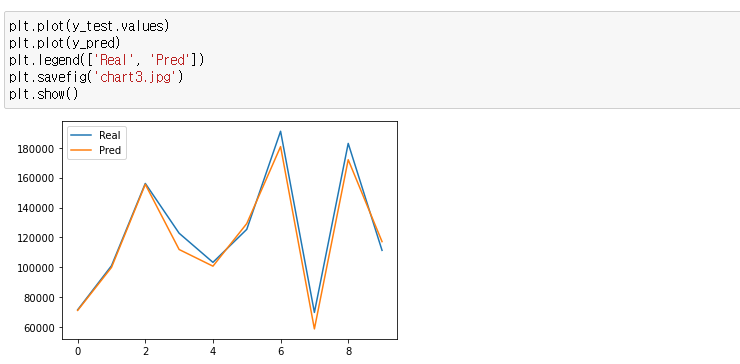
7) 예측값과 실제값 비교

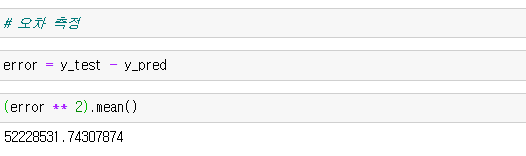
8) 오차와 성능 측정
오차 측정 : 실제값 - 예측값
성능 측정 : MSE(Mean Squared error) : 오차의 제곱에 대한 평균을 취한 값을 구하여 성능을 측정하였다.
9) 실제값과 예측값 시각화